Tambola: One Ticket, Trillions of Possibilities
Design, trade-offs, alternate architectures (EC2/Redis/Kubernetes) and why I picked Lambda + DynamoDB for this project.
Check out the generator here if you haven't already.
TLDR;
The generator deterministically maps a monotonically increasing seed to a tambola ticket. For each request I reserve seeds (atomically) and run a pure generator function that converts a seed into a 3×9 ticket. This approach is cheap (only a counter in storage), reproducible and very fast.
Because the expected throughput is modest (roughly ~1k API calls/day in the initial usage patterns), I chose a serverless Lambda implementation that increments a DynamoDB counter. Below I explain other approaches (EC2 servers prefetching seeds into memory, using Redis, storing all generated tickets) and compare pros/cons so the right architecture can be picked as load changes.
The problem - how to generate unique Tambola tickets?
A Tambola (or Housie) ticket has a strict structure: it is a 3×9 grid with exactly 15 numbers filled in and 12 blanks. Each row contains exactly 5 numbers, and each column corresponds to a specific number range:
- Column 1 → numbers 1-9
- Column 2 → numbers 10-19
- …
- Column 9 → numbers 80-90
Numbers in each column are sorted top to bottom, and the distribution of blanks ensures that every row and column follows the standard Tambola rules.
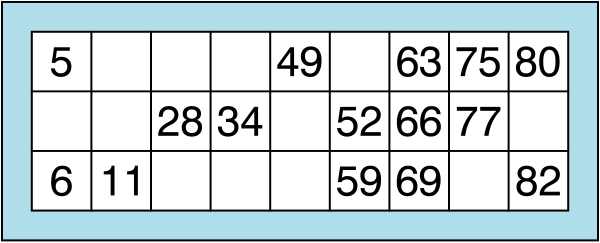
How a Tambola ticket is generated? As explained here ticket generation follows a two-pass algorithm:
-
Pass 1: For each row, a fixed number of cells are randomly marked as blanks
(based on
numsPerRow), while ensuring that each column retains at least one number. - Pass 2: The remaining non-blank cells are filled column by column using unique random numbers from predefined ranges specific to each column. Numbers in each column are sorted in ascending order to maintain the standard Tambola format.
How many tickets are possible?
The number of valid Tambola tickets is mind-bogglingly huge. Roughly:
- We must choose
15filled cells out of27possible grid positions →C(27, 15) ≈ 17 millioncombinations. - Within these placements, numbers from each column’s allowed range must be chosen and sorted.
-
Accounting for all valid distributions, the total possible unique Tambola tickets is mind-bogglingly huge (~
1027+).Refer: Discussion on Math Exchange
To give perspective: even if you generated 1 billion tickets per day, it would still take 25 million years before you would run out of unique tickets.
Can we just store all tickets?
A simple approach is to pre-generate and store tickets in a database. If we only needed a few million tickets, this would be perfectly fine:
- Each ticket can be stored as a string or serialized array.
- A few million tickets would only take a few GBs of storage, easily manageable in DynamoDB or any RDBMS.
But storing all possible tickets is completely infeasible:
- At
1027tickets, even if each ticket used just 100 bytes of storage, we would need1029 bytes(~100 billion exabytes) of space. - That’s far beyond the storage capacity of any cloud provider today.
So while storing a small subset is workable for practical play, storing the entire space of tickets is impossible.
The idea of seeds + PRNG
Instead of storing tickets, we can use a pseudo-random number generator (PRNG). The key trick: a PRNG seeded with a unique integer will always produce the same sequence of random numbers. That means:- Input: a unique integer seed (e.g. 42).
- Process: run the ticket generation algorithm using random numbers from the PRNG.
- Output: always the same unique Tambola ticket for that seed.
This gives us a deterministic, one-to-one mapping between seed → ticket. As long as seeds are never reused, no two tickets will ever collide.
Why is this powerful?
- We no longer need to store tickets, only the last used seed.
- Incrementing the seed by 1 gives the next unique ticket instantly.
- We can skip around the seed space arbitrarily without worrying about collisions.
In other words: the seed acts as a compact index into an unimaginably large space of valid tickets, without needing to precompute or store them.
Current architecture (chosen)
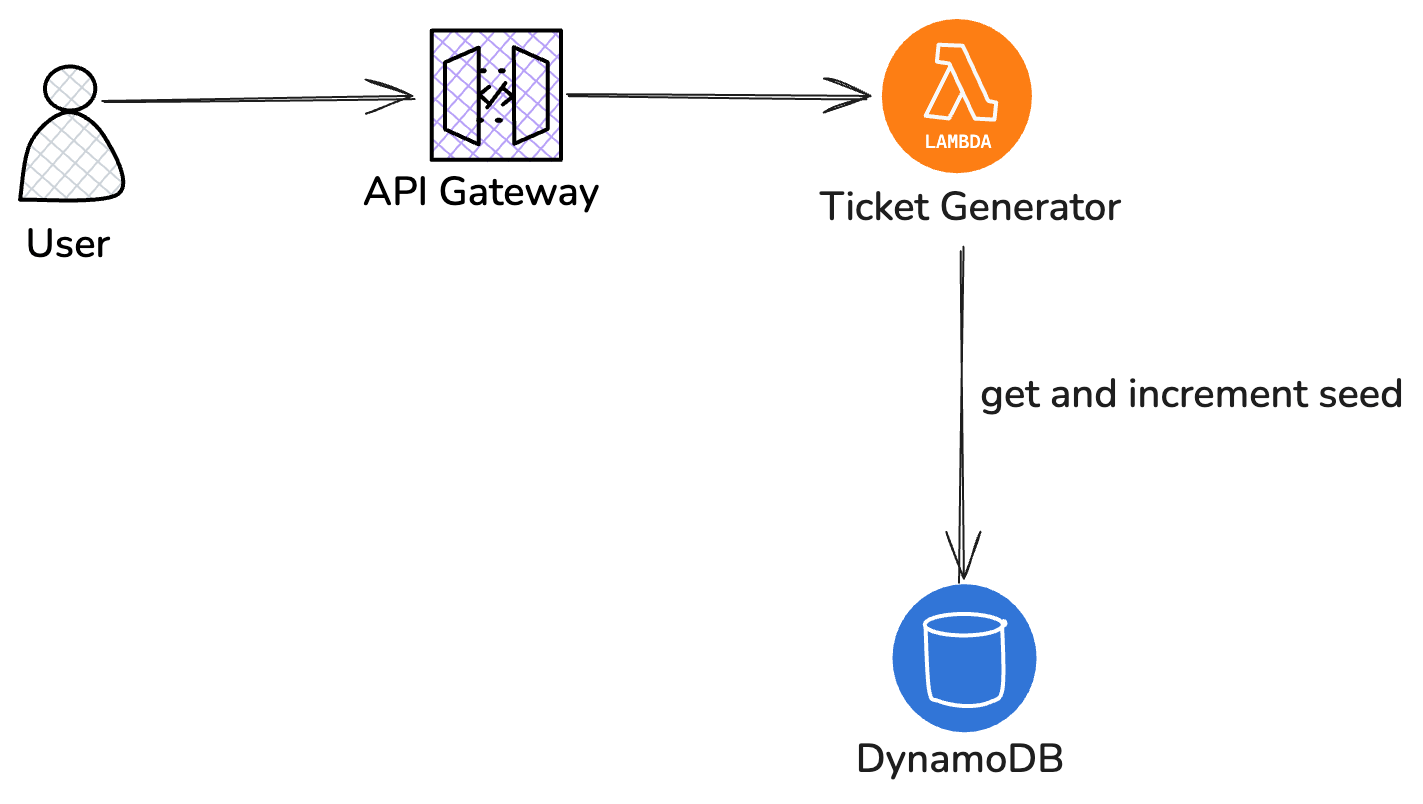
Lambda + DynamoDB (what I run now)
How it works
- API Gateway → Lambda (Java 21) request.
- Lambda calls DynamoDB
UpdateItemto atomically increment the seed byN(N = number of tickets this call will generate). DynamoDB returns the updated value. - Lambda reads this numeric value and uses it as a
longseed in Java to generate N deterministic tickets (seed, seed+1, ... seed+N-1) and returns them to the client.
You can view the source code for the lambda here.
Important note: since the seed is updated atomically in DynamoDB, uniqueness is preserved across concurrent Lambda invocations. To reduce DynamoDB calls we can use block allocation (reserve 100-1000 seeds at once) which cuts DB calls dramatically. Some seeds may be wasted if a container dies - typically acceptable.
Quick cost & longevity note
The PRNG requires a Java long seed. This raises the question: can we ever exceed
long limits?
Java long max = 9,223,372,036,854,775,807. At 1,000 API calls/day × 10
tickets = 10,000 tickets/day, that counter lasts for a trillion years! Even at an absurd billion
tickets/day, the long lasts ~25 million years.
So using the DynamoDB numeric as a Java long seed is safe for all practical
purposes.
Other approaches explored -
1. Long-running servers (EC2 instances) with in-memory prefetch
How it works: one or more EC2 instances (or containers) run the ticket generator service. Each instance periodically requests a block of seeds from a central counter (DynamoDB / Redis / RDBMS) - e.g. “give me seeds 10001-11000”. The server stores that block in memory and dispenses seeds from memory until the block is exhausted, then asks again.
Pros
- Very low latency after prefetch - no DB call per request while block available.
- Lower DB operations cost when block size is large (one DB call per block).
- Predictable performance, good for high QPS and low-latency SLAs.
- Servers can cache other heavy resources (e.g., precomputed permutations) in RAM to speed generation.
Cons
- State in memory → more complexity when scaling (need careful handling of wasted seeds and coordinated allocation).
- Operational overhead (managing EC2, autoscaling, health checks, deployments).
- Single-instance memory loss (or crash) wastes that instance’s allocated seeds unless it is checkpointed back to DB.
- Cost: always-on servers cost more than serverless for low traffic.
Practical notes
- Use a conservative block size (e.g., 500-5000) depending on request rate and memory constraints.
- Optionally persist the per-instance current pointer periodically to a DB to reduce wasted seeds on crash.
- Combine with load-balancer + instance health checks so failed instances are replaced quickly.
2. Redis (ElastiCache / MemoryDB) as the central counter
How it works: run a Redis counter (INCR / INCRBY) as the authoritative seed allocator. Lambdas or EC2 servers call Redis to reserve ranges (INCRBY N) and use the returned value as the block end.
Pros
- Extremely low latency and high throughput for counter ops.
- Natural for block allocation + very high QPS scenarios.
- Atomic INCR semantics make allocation trivial.
Cons
- Redis is stateful and requires cluster management / failover planning (or use managed ElastiCache/MemoryDB).
- Cost is higher than DynamoDB at small scale - but gives the best latency at larger scale.
3. Containerized microservices (ECS/EKS) with leader election
How it works: deploy many containers; perform leader election or use a central allocator service (which itself can prefetch ranges from DB/Redis), endpoints request seeds from the allocator. Containers handle generation; the allocator owns counter updates.
Pros
- Flexible; can co-locate heavy compute and caching logic.
- Works well with CI/CD and infra-as-code.
Cons
- Complex to build and operate; requires orchestration knowledge.
4. Store every generated ticket in a database (dedupe on create)
How it works: generate candidate tickets (random or deterministic), compute canonical serialization or hash, check DB for existence. If new, store and return; if duplicate, retry.
Pros
- Absolute guarantee of no duplicates if we check before inserting.
- Enables queries on historical tickets (who generated what, when).
Cons
- High DB read/write load. For every generated ticket we might have 1+ reads and 1 write (or conditional write).
- Costs and latency grow with traffic-expensive at scale.
- Complexity in indexing and storage, and we cannot store all mathematically possible tickets (impractical).
Comparative table (decision summary)
| Approach | Best for | Pros | Cons |
|---|---|---|---|
| Lambda + DynamoDB | Low-to-moderate throughput, simple infra | Serverless, durable atomic updates, cheap at low QPS | DB call per allocation unless batching; cold start latency |
| EC2 with in-memory prefetch | High throughput, low-latency requirements | Lowest per-request latency, fewer DB ops | Ops overhead, wasted seeds on crashes, more expensive for low traffic |
| Redis (INCR) | Very high QPS counter | Fast, atomic increments, simple semantics | Stateful service, managed cluster cost |
| Store every ticket in DB | When historical audit or absolute uniqueness is required | Guaranteed dedupe, queryable history | Huge storage & I/O costs; impractical at large scale |
Practical patterns & hybrid options
Batch allocation + serverless
Combine Lambda with block allocation: each Lambda invocation asks DynamoDB for a block (e.g., 1000 seeds) using a single UpdateItem and returns the block starting value. The Lambda (or the container) dispenses seeds from that block in-memory until exhausted. This reduces DynamoDB calls substantially while keeping serverless benefits.
Layered approach
For medium scale, run a small number of EC2/container-based seed distributors that prefetch from DynamoDB/Redis and serve Lambdas/clients. This centralizes block allocation and lets front-end Lambdas remain stateless and cheap.
When to move from Lambda → EC2/Redis
- When average latency requirements are < 50 ms and DB call latency becomes the dominant factor.
- When cost analysis shows many small Lambda invocations plus DynamoDB calls cost more than a small fleet of servers.
- When we need heavy per-instance caching or GPU/accelerated tasks (not relevant for tambola, but worth noting).
Why Lambda + DynamoDB was chosen
For this project I picked Lambda + DynamoDB because:
- Traffic assumption: expected modest traffic (~1k calls/day). At this level, Lambda invocation + occasional DynamoDB UpdateItem calls are inexpensive.
- Operational simplicity: no server fleet to manage, simpler CI/CD, easy updates and deployment.
- Durability & correctness: atomic updates in DynamoDB guarantee unique seed allocation without implementing distributed locks.
If throughput increases dramatically, it's straightforward to evolve the architecture to EC2/Redis or container-based prefetching - the generator code (seed → ticket) does not change; only the allocation layer does.
Wrapping up
If you’ve read this far – thank you! 🙌 What started as a simple Tambola ticket turns out to be backed by a surprising amount of math, probability, and clever engineering. Hopefully this gave you a new appreciation for how something so familiar can hide so much complexity under the hood. Next time you play Tambola, remember – behind every ticket is a universe of combinatorics!